Project Overview: End-to-End MLOps Ecosystem
This project is a comprehensive demonstration of applied Machine Learning operations (MLOps) and distributed system design which I did while I was studing, therefore it is not a production-ready system and can be improved a lot. This project aims to be a simple example of a complete microservices ecosystem capable of automating the entire data lifecycle: from raw synthetic data ingestion via external services, through unsupervised discovery and supervised training, down to real-time inference via a stateless REST API.
For a pure algorithmic deep-dive comparing classification techniques without the architectural overhead, see my ML Classification by Lifestyle project.
Architectural Paradigm: Separation of Concerns
- Decoupled Microservices: The system is divided into strict bounded contexts (Data Provider, Storage, Backend, UI), ensuring that the predictive engine and the presentation layer can evolve or scale independently.
- Stateless Orchestration (FastAPI): The backend acts as a strict contract enforcer. It holds no local state, relying purely on defined schemas to validate incoming biological traits. This stateless nature ensures horizontal scalability in production environments.
- Dumb Client Presentation (Streamlit): The UI is intentionally decoupled from the ML logic. It acts purely as a consumer of the API, enforcing the boundary between visual interaction and mathematical processing.
Data Governance & Reproducibility (Object Storage)
A critical pillar of modern ML architecture is reproducibility. Instead of relying on traditional relational databases, this system implements an S3-compatible Object Storage layer (MinIO). This acts as an immutable ledger divided into functional domains:
Raw Data Lakes: Freezing the state of ingested data at the time of creation.
Artifact Registries: Serializing the trained mathematical models (the "packaged brain") alongside their cross-validation metrics.
Inference Logs: Storing timestamped predictions to allow future auditing of model decisions and drift detection.
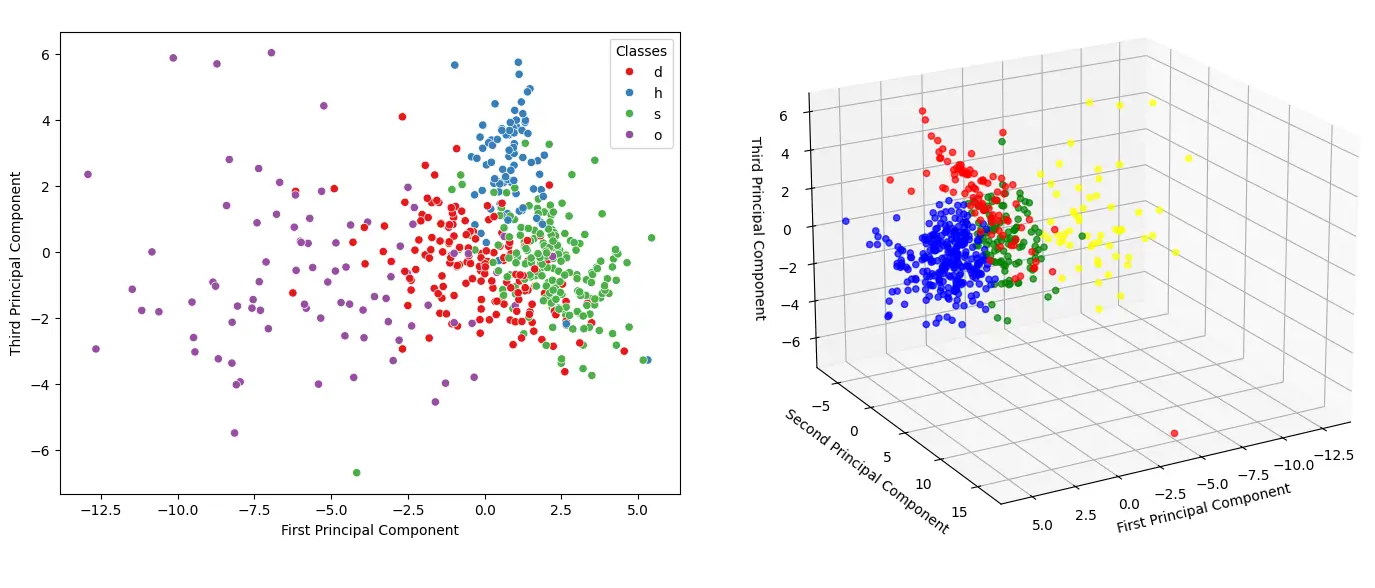
Analytical Phase 1: Unsupervised Discovery & Latent Topology
Before assigning deterministic labels, the system explores the raw data using unsupervised clustering (e.g., HDBSCAN/KMeans). This phase is crucial for discovering the latent topology of the dataset based purely on physical similarities. By grouping features without prior knowledge, we can detect statistical anomalies (outliers), assess the natural separability of the animal classes, and optionally engineer derived features (cluster IDs) to enrich the downstream classification.
Analytical Phase 2: Supervised Inference & Ensembles
The core predictive engine leverages supervised learning with a focus on variance reduction. Rather than trusting a single estimator, the architecture implements Ensemble methods (such as Hard/Soft Voting Classifiers) alongside extensive Grid Search hyperparameter tuning. This "wisdom of the crowds" approach aggregates the confidence of multiple algorithms, significantly minimizing the margin of error. Furthermore, preprocessing logic (scaling, encoding) is strictly encapsulated within Pipelines to prevent data leakage during Stratified K-Fold cross-validation.
Ecosystem Alignment & Scalability Vision
While currently orchestrated via Docker Compose for self-contained execution, the architectural patterns mirror enterprise-grade MLOps standards. The use of a stateless API and discrete Object Storage means the transition from a single node to a cloud-native Kubernetes deployment is seamless. Future iterations could easily replace the synchronous training loop with asynchronous message queues (e.g., Celery) and swap direct serialization for formal model registries like MLflow or BentoML.
System Information Flow
| Component Boundary | Responsibility | Interaction Contract |
|---|---|---|
| Data Service (External) | Generates raw, unlabeled synthetic biological data. | HTTP POST -> Backend Ingestion |
| MinIO (Storage) | Immutable blob storage for datasets, artifacts, and logs. | I/O operations exclusively via Backend |
| FastAPI (Backend) | Orchestrates training, serves models, enforces validation. | Consumes Storage; Serves UI |
| Streamlit (Frontend) | Provides user interfaces for prediction and historical auditing. | HTTP GET/POST -> Backend API |