CV RAG: A Local, End-to-End Retrieval-Augmented Generation Platform
CV RAG is a local-first RAG platform built around a synthetic candidate database: it generates fake CVs, stores the rendered PDFs, normalizes and chunks their content, indexes them with hybrid dense + sparse vectors in Qdrant, and serves a LangGraph-orchestrated assistant that answers natural-language questions over the indexed candidates with cited sources.
The system is split into four independent modules, cv_factory (synthetic CV generation), cv_ingestion (parsing, LLM normalization and chunking), rag (hybrid retrieval and the assistant graph) and cv_rag.api (FastAPI + Chainlit), all calling an OpenAI-compatible LiteLLM gateway so the underlying model provider (Ollama, vLLM, OpenAI, Anthropic, ...) can change with a single YAML edit and zero code changes.
1. High-Level Architecture
Data flows in one direction, from synthetic generation to a queryable assistant, with each stage owned by its own module:
Pipeline Topology
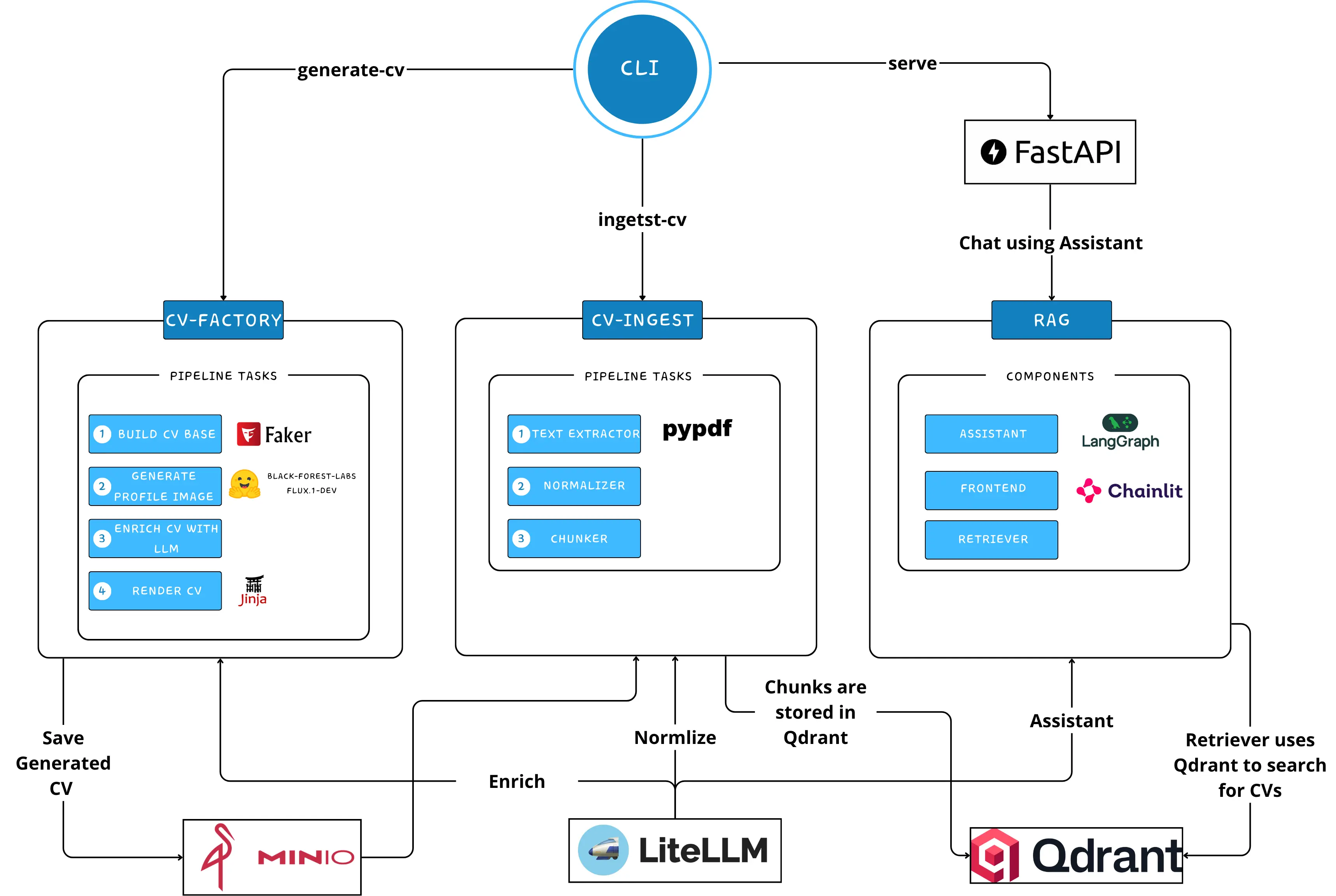
Module Responsibilities
cv_factory, Builds synthetic CVs from catalog profiles, enriches narrative fields with an LLM, optionally generates a profile image, and renders the final PDF to local disk, MinIO, or both.cv_ingestion, Extracts PDF text, asks the LLM to normalize it into structured data validated by Pydantic, chunks the normalized CV, and indexes the chunks into Qdrant.rag, Hosts retrieval (QdrantCVStore) and the assistant graph: a LangGraph workflow that rewrites queries, routes intent, retrieves candidate chunks under the right strategy, and generates cited answers.cv_rag.api, Builds the FastAPI app, mounts the REST endpoints under/api/v1, and mounts the Chainlit chat UI at/chainlit.
2. CV Factory: A Four-Stage Generation Pipeline
run_pipeline chains four independent tasks, each one consuming the previous task's output and nothing else, no global state is shared between them. A single bad image generation or render does not corrupt the validated CV data produced earlier in the chain.
Generation Tasks
build_cv_base, Picks a random career profile (e.g. Backend Developer, with seniority-tiered job titles and a weighted skill catalog) from the built-in registry, then uses Faker (es_ESlocale) plus the profile's title/education options to generate a chronologically consistent skeleton: experience entries are generated oldest-first, education end dates are forced to predate the candidate's first job, and the top 8 skills are picked by weight. The result is a fully Pydantic-validatedCVwith deliberately plain placeholder prose, no LLM call happens yet.
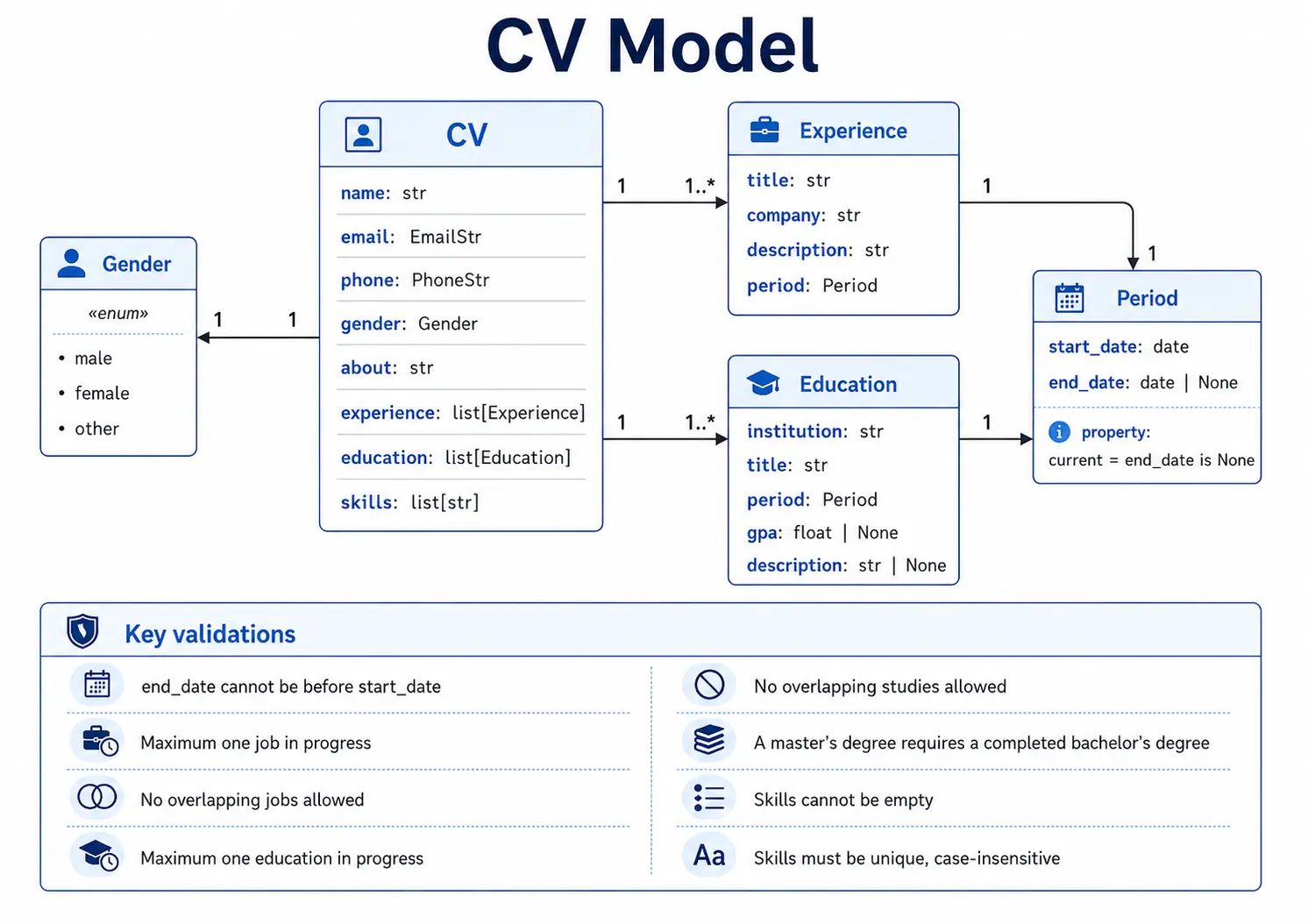
enrich_cv, Sends the validated skeleton to the LLM and asks for narrative-only output (CVEnrichmentOutput): anaboutsummary plus one description per experience/education entry, addressed by zero-based index. Amodel_validatorrejects duplicate indexes, and_validate_shapethen checks the returned index set matches the input exactly, so the LLM can enrich prose but can never add, drop, or reorder structured entries. Enrichment first tries strict JSON-schema mode and falls back to plain JSON-object mode with an explicit reminder if the provider does not support schema-constrained output.generate_profile_image, Calls the Hugging Face Inference router (FLUX.1-schnell) with a gender-aware photorealistic headshot prompt and a random seed per call (diffusion models have no temperature knob, without a fresh seed the router can return a cached image for an identical prompt). The PNG/JPEG bytes are base64-encoded into adata:URI in memory, nothing touches disk. Entirely optional via--skip-image.render_cv, Picks one of three bundled Jinja2/HTML templates (classic_ats,compact,modern_sidebar) and one display alias per section heading (e.g. "Experience" vs "Work History" vs "Career History") at random, both seedable for reproducible runs. This randomizes the visual and lexical shape of generated CVs without touching the underlying data, which matters for testing how robustly the ingestion LLM extracts structure regardless of heading wording or layout. WeasyPrint converts the rendered HTML straight to PDF.
@model_validator(mode="after")
def validate_experience(self) -> "CV":
current_jobs = [j for j in self.experience if j.period.current]
if len(current_jobs) > 1:
raise ValueError("There can only be one ongoing job at a time.")
today = date.today()
ranges = [
(j.period.start_date, j.period.end_date or today, j.company)
for j in self.experience
]
for i, (start_a, end_a, company_a) in enumerate(ranges):
for start_b, end_b, company_b in ranges[i + 1:]:
if max(start_a, start_b) < min(end_a, end_b):
raise ValueError(
f"Employment overlap between '{company_a}' and '{company_b}'."
)
return self3. CV Ingestion: A Four-Stage, Fault-Isolated Pipeline
ingest_cv chains four tasks per file, extract → normalize → chunk → index, and wraps the whole sequence in a single try/except: one malformed CV logs an error and returns a failed CVIngestResult, it never aborts a batch. ingest_directory runs this per-file pipeline under a bounded asyncio.Semaphore (default 4 concurrent workers) and reports a BatchIngestResult with per-file outcomes, so a 500-CV batch ingestion degrades gracefully instead of failing atomically.
Ingestion Tasks
extract_text, Reads every PDF page withpypdf, drops blank pages, and joins the rest with double newlines into one plain-text blob. RaisesUnsupportedCVFormatErrorfor any non-PDF input andEmptyCVTextErrorupstream if extraction yields nothing usable.extract_normalized_cv, A single LLM call turns raw CV text into a strict JSON payload (NormalizedCVLLMOutput,extra="forbid") covering contact info, anaboutsummary, experience, education, skills, certifications, languages, projects, links, and a catch-alladditional_sectionsbucket for anything that does not map to a canonical field (awards, publications, volunteering, references, ...). The system prompt explicitly tells the model to infer sections from content and position when headings are missing or non-English, to never paraphrase descriptions, and to never invent information. The JSON schema sent to the LLM is post-processed to strip Pydantic defaults and mark every propertyrequiredso nullable fields come back as explicitnullinstead of being silently omitted; like enrichment, it falls back to plain JSON-object mode if schema-constrained output is rejected.NormalizedCV.from_llm_payloadthen derivesyears_of_experience,current_titleandcurrent_companyfrom the dated entries, so those facts exist as first-class, filterable metadata instead of being re-inferred at query time.build_chunks, Renders oneCVChunkper non-empty canonical section (contact, about, experience, education, skills, certifications, languages, projects, links, additional), so a CV typically becomes 8–10 chunks. Each chunk'spage_contentis composed from a compact cross-section context header (candidate name, current role, top skills, latest education) plus the section's own text, so a section is retrievable both by its own content and by CV-level facts.QdrantCVStore.index, Batches chunks into upserts of 64 points, embedding dense and sparse vectors lazily through Qdrant'sDocumentquery type rather than computing them client-side.
3a. Why One Chunk Per Section
Unlike fixed-window chunking, splitting a CV by canonical section keeps each chunk a coherent semantic unit, a candidate's full work history never gets fragmented mid-sentence, and skills never bleed into an unrelated experience description. For a deeper comparison of chunking strategies and why entity- or section-level chunking beats naive fixed windows for structured documents like CVs, see my blog post on Chunking Strategies for RAG.
4. Hybrid Retrieval: Dense + Sparse + Reranking
QdrantCVStore indexes every chunk with two named vectors in the same point, a dense embedding and a sparse (BM25) embedding, computed by Qdrant itself via fastembed-backed Document queries rather than a separate embedding service. The dense model is asymmetric: it was trained with literal "query: " / "passage: " text prefixes that tell it which side of the search it is embedding, so E5_QUERY_PREFIX is added to every search query and E5_PASSAGE_PREFIX to every indexed chunk, but never to the sparse text, which matches on raw terms and would only pick up noise from the prefix. For the theory behind dense vs. sparse retrieval, RRF fusion, and how cross-encoder reranking actually improves precision, see my blog post on Information Retrieval: Dense, Sparse & Reranking.
Retrieval Model Stack
| Component | Model | Why |
|---|---|---|
| Dense embeddings | intfloat/multilingual-e5-large | Strong multilingual retrieval; needs query/passage prefixes |
| Sparse embeddings | Qdrant/bm25 | Language-agnostic lexical matching for mixed-language CVs |
| Reranker | jinaai/jina-reranker-v2-base-multilingual | Fast multilingual cross-encoder for final precision |
4a. Metadata Filters: Fuzzy Where It Helps, Exact Where It Matters
build_metadata_filter translates structured filters (skills, companies, degrees, institutions, certifications, current title/company, candidate name, years-of-experience range, ...) into a Qdrant Filter. Free-text-ish fields, candidate_name, current_title, current_company, companies, degrees, institutions, certifications, use Qdrant's MatchText against a word-tokenised full-text index, giving case-insensitive, partial-word matches that absorb punctuation drift between CVs (e.g. "S.C.P" vs "S.C.P.", "BSc" vs "B.Sc."). Low-cardinality, single-token fields, skills, languages, section, email, stay exact MatchValue keyword matches, since fuzzy matching there would only add false positives. Every value is run through _normalise (NFC/NFD unicode normalization, diacritic stripping, lowercasing, whitespace collapsing) before being compared, both when stored and when queried, so accent typos and casing differences never silently break a filter. years_of_experience gets a dedicated integer payload index for gte/lte range queries.
def _normalise(text: str) -> str:
# NFC first, then decompose to strip combining diacritical marks
nfd = unicodedata.normalize("NFD", unicodedata.normalize("NFC", text))
stripped = "".join(ch for ch in nfd if unicodedata.category(ch) != "Mn")
lowered = stripped.lower()
return re.sub(r"\s+", " ", lowered).strip()Three Retrieval Strategies, Picked by Intent
search_hybrid, Pure dense+sparse RRF fusion. With reranking off, returns the toplimitfused candidates directly; with reranking on, each branch oversamples toRERANK_PREFETCH_LIMIT = 50candidates before the cross-encoder re-scores them, following standard 3-6x oversampling guidance for two-stage retrieval. Used for open-ended semantic queries with no structured constraints ("who has strong leadership experience?").search_metadata, Scroll-based metadata filter, no vector scoring at all, deduplicated bysource_path. Critically, when a CV has several chunks matching the filter, it keeps the chunk from the section that actually contains the matched fact (_FIELD_SECTION_PRIORITY, e.g. acompaniesfilter prefers theEXPERIENCEchunk), instead of an arbitrary chunk that merely carries the same denormalised CV-level metadata. Used for hard lookups ("list all candidates with a PhD").search_metadata_then_rerank, Two-phase: scroll every chunk passing the metadata filter (up toscroll_limit=100, so no candidate is dropped for a weak initial vector score), then rerank all of them with the cross-encoder against the free-text query. Used when structured constraints and a comparative or semantic intent combine ("among Python developers with 5+ years, who is the strongest?"). Falls back tosearch_hybridwith reranking when no filter is actually present.
4b. Deduplication Lives at the Citation Layer, Not the Search Layer
search_hybrid and search_metadata_then_rerank deliberately return the top limit chunks, not the top limit candidates: since a CV is chunked one-per-section, the strongest match can legitimately contribute more than one chunk (its "experience" and "skills" sections both ranking high), and collapsing to one chunk per CV there would silently drop a top candidate's second-best section to make room for a weaker single-section match from someone else. The citation list shown to the user is deduplicated by source_path separately, in chunks_to_sources, so the UI never shows the same CV twice even though the context fed to the LLM can legitimately include it more than once.
5. The RAG Assistant: A LangGraph State Machine
The assistant is a compiled LangGraph StateGraph with its own MemorySaver checkpointer, so conversation state persists per thread_id across turns. Every user turn is first rewritten into a standalone query (resolving references to earlier turns), then classified by an intent router that also extracts structured MetadataFilters (skills, companies, degrees, years of experience, ...) in the same LLM call. A conditional edge then picks one of the three retrieval strategies above, or routes straight to a fixed out-of-scope answer when the question has nothing to do with the candidate database.
Assistant Graph Topology
Node Responsibilities
rewrite_query, Rewrites the latest user message into a standalone query using recent chat history, so short follow-ups ("what about her education?") still carry the needed context downstream.route_intent, One structured LLM call classifies the rewritten query intoout_of_scope/metadata/hybrid/hybrid_filteredand extractsMetadataFiltersat the same time, avoiding a second round trip.metadata_search/hybrid_search/hybrid_filtered_search, The three retrieval strategies described above, selected byroute_after_intentbased on the route plus whether any filter was actually extracted.generate_answer, Builds the final prompt from the retrieved chunks and streams or returns the answer; falls back to a fixed message if generation produces empty content.out_of_scope, Returns a fixed, non-LLM answer for questions unrelated to the candidate database, short-circuiting straight toENDwithout touching retrieval.
def route_after_intent(state: AssistantState) -> str:
route = state.get("route", IntentRoute.HYBRID)
filters = state.get("metadata_filters") or MetadataFilters()
has_filters = filters.has_any()
if route == IntentRoute.OUT_OF_SCOPE:
return "out_of_scope"
if route == IntentRoute.METADATA:
return "metadata_search" if has_filters else "hybrid_search"
if route == IntentRoute.HYBRID_FILTERED:
return "hybrid_filtered_search" if has_filters else "hybrid_search"
return "hybrid_search"5a. Grounded Answers with Source Citations
generate_answer builds its prompt from the retrieved chunks formatted with their candidate, origin path, section and score, and streams tokens through an optional callback (used by the Chainlit UI). The citation list shown to the user is deduplicated by source_path in chunks_to_sources, while the context fed to the LLM is not deduplicated, for the same reason described above: one CV can legitimately contribute several of its strongest sections.
Retrieval quality directly bounds answer quality, so evaluating what got retrieved, not just the final text, matters before trusting any of this in production. For retrieval metrics, LLM-based metrics, and a walkthrough of RAGAS, see my blog post on Evaluating RAG Systems: Retrieval Metrics, LLM Metrics and RAGAS.
6. LiteLLM: One Gateway, Any Provider
Every LLM call, CV enrichment, normalization, query rewriting, intent routing, and answer generation, goes through LiteLLM's OpenAI-compatible proxy instead of a provider-specific SDK. Swapping the backing provider is a litellm_config.yaml edit, not a code change. The app distinguishes a default model (routing, extraction, contextualization) from a quality model (final answer generation), both configured purely through environment variables. For a deeper walkthrough of LiteLLM's architecture, proxy modes and why a unified gateway pays off once you have more than one LLM call site, see my blog post on LiteLLM: One Interface for Every LLM Provider.
model_list:
- model_name: default-llm
litellm_params:
model: openai/your-model-name
api_base: http://your-inference-server:8000/v1
api_key: not-needed
- model_name: quality-llm
litellm_params:
model: openai/your-model-name
api_base: http://your-inference-server:8000/v1
api_key: not-needed7. Infrastructure: Docker Compose
Local development spins up three services, no orchestration platform required:
Docker Compose Services
| Service | Role | Port |
|---|---|---|
| litellm | Unified LLM gateway | 4000 |
| minio | Local S3-compatible artifact storage for generated CV PDFs | 9100 / 9101 |
| qdrant | Vector database for hybrid CV retrieval | 6333 |
Further Reading
| Resource | Use it to... |
|---|---|
| LiteLLM: One Interface for Every LLM Provider | Understand the unified gateway pattern used for every LLM call in this project. |
| Chunking Strategies for RAG | See why one-chunk-per-section beats naive fixed-window chunking for structured documents like CVs. |
| Information Retrieval: Dense, Sparse & Reranking | Learn the theory behind the dense + sparse + cross-encoder pipeline used by QdrantCVStore. |
| Evaluating RAG Systems: Retrieval Metrics, LLM Metrics and RAGAS | Decide how to measure whether the assistant is retrieving and answering correctly, not just plausibly. |
| MTEB Leaderboard | Compare dense embedding models before swapping the DENSE_MODEL constant. |
| Qdrant — Hybrid Queries | Understand RRF fusion and how to size the prefetch limit relative to the final limit. |
| Cohere — Reranking Best Practices | Reference oversampling ratios for any cross-encoder reranker, not just Cohere's. |